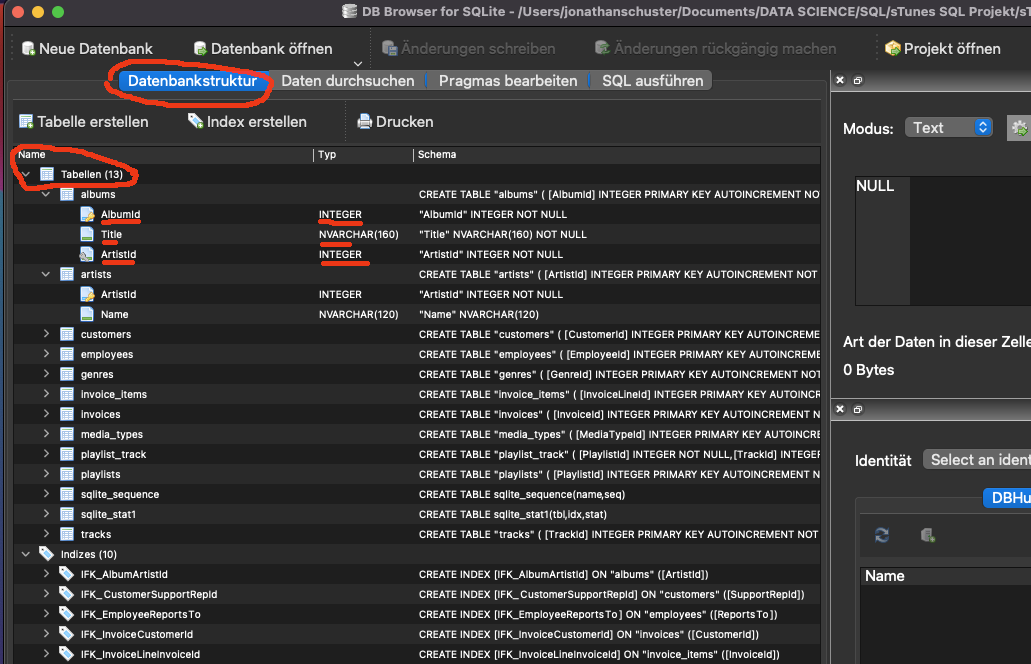
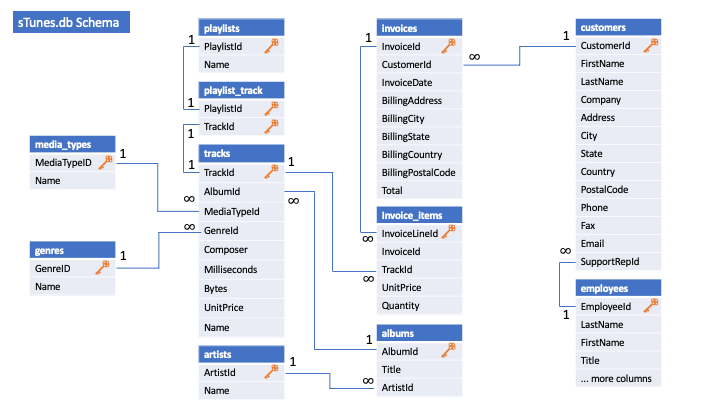
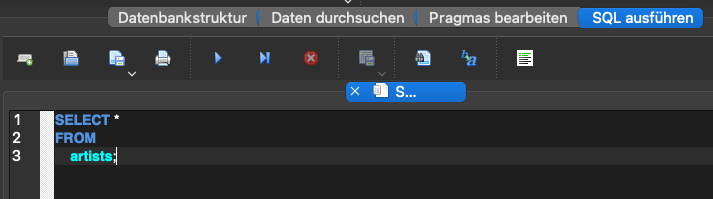
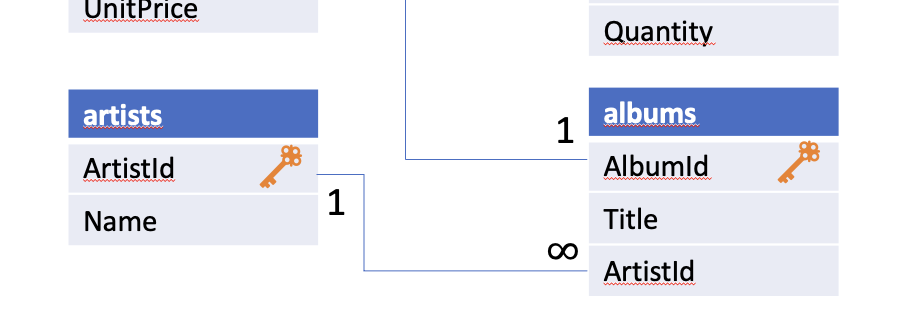
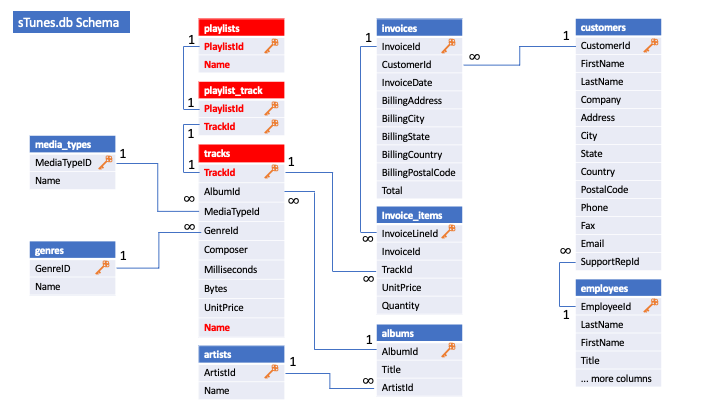
Nachdem wir uns einen Überblick über die Datenbankstruktur verschafft haben, können wir damit anfangen, Informationen aus unserer Datenbank abzufragen. Dazu müssen wir in unserem DB Browser auf den Reiter SQL ausführen wechseln und können dann unsere Befehle in das Fenster schreiben. Durch den Play-Button lassen sich diese dann ausführen.
SELECT
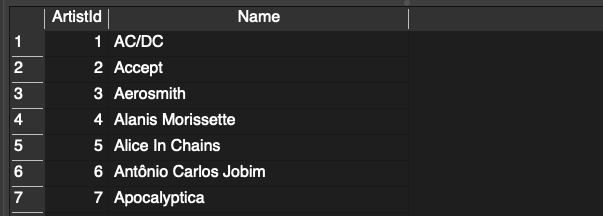
Um Daten abzufragen, können wir das sogenannte SELECT Statement verwenden. Durch den folgenden Befehl können wir alle Einträge mit allen Spalten aus der Tabelle artists ausgeben lassen.
SELECT
*
FROM
artists;
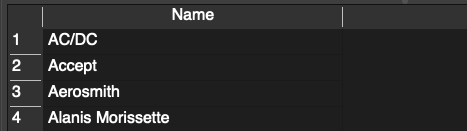
Durch das Sternchen haben wir alle Variablen ausgewählt. Möchten wir genauer festlegen, welche Variablen wir abfragen möchten, können wir dies zwischen SELECT und FROM definieren:
SELECT
Name
FROM
artists;
Dabei können wir beliebig viele Variablen wählen, indem wir sie durch ein Komma trennen. Nur bei der letzten Variable darf kein Komma stehen:
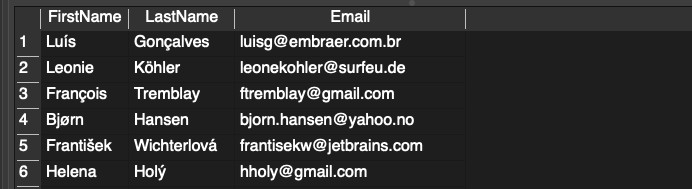
SELECT
FirstName,
LastName,
Email
FROM
customers;
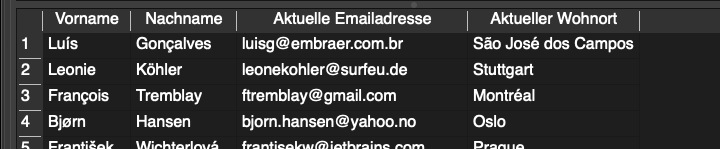
Um die Namen der Spalten in unserer Ausgabe zu verändern, können wir die ausgewählten Variablen in unserem SELECT Statement neu betiteln. Dabei reicht es bei einzelnen Worten, den neuen Titel hinter die Zuordnung AS zu schreiben, während mehrere getrennte Worte wie im folgenden Beispiel durch ’’ oder [ ] umschlossen werden müssen:
SELECT
FirstName AS Vorname,
LastName AS Nachname,
Email AS 'Aktuelle Emailadresse',
City AS [Aktueller Wohnort]
FROM
customers;
WHERE
Um Daten genauer filtern zu können und bestimmte Informationen ausfindig zu machen, können wir den Befehl WHERE und verschiedene Operatoren nutzen.
Zu den wichtigsten Operatoren zählen:
Vergleiche:
= gleich
> größer als
< kleiner als
>= größer oder gleich
<= kleiner oder gleich
<> ungleich
und Logische Operatoren:
BETWEEN
IN
LIKE
AND
OR
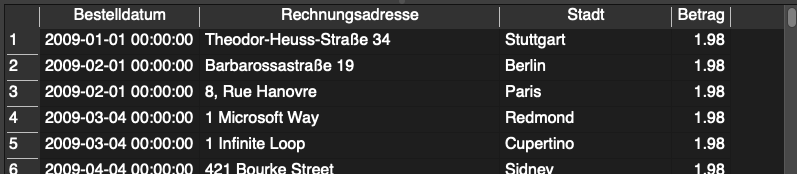
Möchten wir zum Beispiel wissen, welche Rechnungen aus unserer invoices Tabelle einen Gesamtbetrag von genau 1.98$ (Total = 1.98) aufweisen, wann die Bestellungen getätigt worden sind (InvoiceDate), aus welcher Stadt (BillingCity) und mit welcher Rechnungsadresse (BillingAddress), können wir folgenden Befehl ausführen:
SELECT
InvoiceDate AS Bestelldatum,
BillingAddress AS Rechnungsadresse,
BillingCity AS Stadt,
Total AS Betrag
FROM
invoices
WHERE
Total = 1.98
ORDER BY
InvoiceDate;
Ebenso können wir mit dem BETWEEN Operator herausfinden, welche Rechnungen einen Gesamtbetrag zwischen 1.98 und 5.00 aufweisen:
SELECT
InvoiceDate AS Bestelldatum,
BillingAddress AS Rechnungsadresse,
BillingCity AS Stadt,
Total AS Betrag
FROM
invoices
WHERE
Total BETWEEN 1.98 AND 5.00
ORDER BY
InvoiceDate;

Um nach Text-Daten zu filtern, müssen wir den entsprechenden Text lediglich mit Anführungszeichen umschließen. So lassen sich wie folgt alle Bestellungen aus Stuttgart abrufen:
SELECT
InvoiceDate AS Bestelldatum,
BillingAddress AS Rechnungsadresse,
BillingCity AS Stadt,
Total AS Betrag
FROM
invoices
WHERE
BillingCity = 'Stuttgart'
ORDER BY
InvoiceDate;
Dabei können wir ganz gleich ob es sich um Zahlenwerte oder Text handelt auch mehrere Kriterien verwenden. Möchten wir z.B. alle Rechnungen aus Stuttgart mit einem Betrag von mehr al 5$, können wir die zweite Bedingung durch AND hinzufügen:
SELECT
InvoiceDate AS Bestelldatum,
BillingAddress AS Rechnungsadresse,
BillingCity AS Stadt,
Total AS Betrag
FROM
invoices
WHERE
BillingCity = 'Stuttgart' AND Total > 5
ORDER BY
InvoiceDate;

Durch den Operator IN können wir zudem festlegen, dass mehrere Ausprägungen einer Variable in Betracht gezogen werden sollen. So lassen sich wie folgt alle Rechnungen aus Stuttgart oder Berlin abfragen. Wir erhalten praktisch alle Einträge, bei denen der Wert der Variable BillingCity in unserer Liste vorkommt.
SELECT
InvoiceDate AS Bestelldatum,
BillingAddress AS Rechnungsadresse,
BillingCity AS Stadt,
Total AS Betrag
FROM
invoices
WHERE
BillingCity IN ('Stuttgart','Berlin')
ORDER BY
InvoiceDate;

Wenn wir nach Ergebnissen suchen, die ein Kriterium nur teilweise erfüllen sollen, zum Beispiel alle Rechnungen von Städten, die mit “B” anfangen, können wir den Operator LIKE verwenden. Dabei ist durch ein %-Zeichen zu definieren, ob die Buchstaben vor, hinter oder sowohl vor als auch hinter dem gewünschten Inhalt beliebig sein können:
Durch BillingCity LIKE ‘B%’ erhalten wir alle Städte die mit B beginnen. (Brüssel, etc.)
Durch BillingCity LIKE ‘%T’ erhalten wir alle Städte die auf T enden. (Frankfurt, etc.)
Durch BillingCity LIKE ‘%k%’ erhalten wir alle Städte die ein K beinhalten. (Stockholm, etc.)
Durch BillingCity LIKE ‘O%O’ erhalten wir alle Städte die mit O beginnen und enden. (Oslo, etc.)
SELECT
InvoiceDate AS Bestelldatum,
BillingAddress AS Rechnungsadresse,
BillingCity AS Stadt,
Total AS Betrag
FROM
invoices
WHERE
BillingCity LIKE '%K%'
ORDER BY
InvoiceDate;

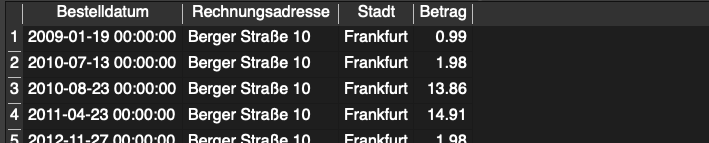
Nützlich wird dies vor allem in Situationen, in denen wir vielleicht nicht wissen wie genau die Eingabe der Daten erfolgt ist oder wir nach kurzen Inhalten in langen Texten filtern möchten. Suchen wir beispielsweise alle Rechnungen mit der Adresse “Berger Straße” und wissen dabei nicht, ob das Wort Straße in der Eingabe ausgeschrieben oder gekürzt wurde und um welche Hausnummer es sich handelt, können wir mit der folgenden Abfrage alle Einträge erhalten, in denen das Wort Berger in der Rechnungsadresse vorgekommen ist:
SELECT
InvoiceDate AS Bestelldatum,
BillingAddress AS Rechnungsadresse,
BillingCity AS Stadt,
Total AS Betrag
FROM
invoices
WHERE
BillingAddress LIKE '%Berger%'
ORDER BY
InvoiceDate;
Nutzung mehrerer Operatoren
In der Realität werden diese Filter meist komplexer und verwenden mehrere Operatoren wie AND und OR zugleich. Dabei gilt es bestimmte Reihenfolgen und Regeln zu beachten, um nicht das falsche Ergebnis zu erhalten. Ohne die Verwendung von Klammern werden die Bedingungen auf beiden Seiten des AND automatisch zusammengefasst. Dies entspricht jedoch nicht immer unserem Vorhaben.
Möchten wir beispielsweise eine Liste aller Rechnungen mit einem Betrag über 1.50$ aus Städten die entweder mit D oder P beginnen, könnten wir die Bedingung Total > 1.50 über AND mit BillingCity Like ‘p%’ OR BillingCity Like ‘d%’ verbinden. Ohne Klammern erhalten wir jedoch das folgende Ergebnis:
SELECT
InvoiceDate AS Bestelldatum,
BillingAddress AS Rechnungsadresse,
BillingCity AS Stadt,
Total AS Betrag
FROM
invoices
WHERE
Total > 1.50 AND BillingCity LIKE 'p%' OR BillingCity LIKE 'd%'
ORDER BY
Total;

Wie wir an den ersten beiden Einträgen mit Betrag unter 1.50$ sehen können, hat SQL unseren Befehl anders verstanden, als wir es uns gewünscht haben. Die beiden Kriterien vor dem OR wurden zusammengefasst, während alles nach dem OR einzeln und damit ohne Rücksicht auf den Betrag betrachtet wurde.
Wir haben also alle Einträge erhalten, die entweder der Bedingung “größer als 1.50$ und aus Stadt mit p am Anfang” oder der Bedingung “Stadt mit d am Anfang” entsprechen.
Um das korrekte Ergebnis zu erhalten, müssen wir Klammern so setzen, dass alle Bedingungen korrekt interpretiert werden, also so, dass zunächst alle Rechnungen mit den gewünschten Beträgen gesucht und erst anschließend die weiteren Bedingungen angewendet werden.
SELECT
InvoiceDate AS Bestelldatum,
BillingAddress AS Rechnungsadresse,
BillingCity AS Stadt,
Total AS Betrag
FROM
invoices
WHERE
Total > 1.50 AND (BillingCity LIKE 'p%' OR BillingCity LIKE 'd%')
ORDER BY
Total;